
Introduction
Dans les billets précédents, nous avons établi que l’Analyse Discriminante Linéaire (ADL) et la régression MCO donnent la même direction de projection, et nous avons mis ce résultat en pratique avec LSQR sur l’algorithme Fisherfaces.
LSQR est une méthode de Krylov : elle construit itérativement un sous-espace de Krylov de $\mathbf{X}_c^\top \mathbf{X}_c$ et y cherche la meilleure approximation. Sa convergence est excellente mais chaque itération nécessite deux produits matrice-vecteur globaux (un avec $\mathbf{X}_c$, un avec $\mathbf{X}_c^\top$).
Ce billet explore une autre famille de solveurs : les méthodes de Kaczmarz (aussi appelées méthodes par rangées ou row-action methods). Leur idée-clé est différente : au lieu d’exploiter toute la matrice à chaque étape, on tire une seule rangée au hasard et on effectue une projection sur l’hyperplan correspondant. Cela rend chaque itération extrêmement bon marché — $O(d)$ opérations — et bien adaptée aux très grandes matrices.
La méthode de Kaczmarz classique
Géométrie des projections successives
Considérons le système linéaire
\[A\mathbf{x} = \mathbf{b}, \qquad A \in \mathbb{R}^{m \times n},\; \mathbf{b} \in \mathbb{R}^m.\]Chaque équation $\mathbf{a}_i^\top \mathbf{x} = b_i$ (rangée $i$ de $A$) définit un hyperplan affin $H_i = {\mathbf{y} \in \mathbb{R}^n : \mathbf{a}_i^\top \mathbf{y} = b_i}$. La solution exacte $\mathbf{x}^*$ est l’intersection de tous ces hyperplans.
La projection orthogonale de $\mathbf{x}$ sur $H_i$ est :
\[P_{H_i}(\mathbf{x}) = \mathbf{x} + \frac{b_i - \mathbf{a}_i^\top \mathbf{x}}{\|\mathbf{a}_i\|^2}\,\mathbf{a}_i.\]L’algorithme de Kaczmarz consiste à appliquer ces projections en séquence :
\[\mathbf{x}^{(k+1)} = \mathbf{x}^{(k)} + \frac{b_{i_k} - \mathbf{a}_{i_k}^\top \mathbf{x}^{(k)}}{\|\mathbf{a}_{i_k}\|^2}\,\mathbf{a}_{i_k},\]où dans la version cyclique on prend $i_k = k \bmod m$, et dans la version aléatoire on tire $i_k$ selon une certaine distribution.

Convergence cyclique
Pour un système consistant ($\mathbf{b} \in \mathcal{R}(A)$), la version cyclique converge mais à une vitesse qui dépend des angles entre les hyperplans. Si deux hyperplans sont presque parallèles, les projections successives oscillent et la convergence est très lente.
Kaczmarz aléatoire (Strohmer & Vershynin, 2009)
Tirage proportionnel aux normes
La version aléatoire tire la rangée $i_k$ avec probabilité
\[p_i = \frac{\|\mathbf{a}_i\|^2}{\|A\|_F^2},\]où $|A|_F^2 = \sum_i |\mathbf{a}_i|^2$ est le carré de la norme de Frobenius. Ce choix est naturel : une rangée $\mathbf{a}_i$ de grande norme définit un hyperplan qui contribue davantage à la géométrie du système, et lui donner plus de poids accélère la convergence.
Théorème de convergence
Théorème (Strohmer & Vershynin, 2009). Soit $A\mathbf{x} = \mathbf{b}$ un système consistant, $\mathbf{x}^*$ sa solution de norme minimale, et $(\mathbf{x}^{(k)})$ la suite produite par le Kaczmarz aléatoire avec $\mathbf{x}^{(0)} = \mathbf{0}$. Alors
\[\mathbb{E}\bigl[\|\mathbf{x}^{(k)} - \mathbf{x}^*\|^2\bigr] \;\leq\; \left(1 - \frac{\sigma_{\min}^2(A)}{\|A\|_F^2}\right)^k \|\mathbf{x}^*\|^2,\]
où $\sigma_{\min}(A)$ est la plus petite valeur singulière non nulle de $A$.
Interprétation. La vitesse de convergence est contrôlée par le rapport $\sigma_{\min}^2(A) / |A|_F^2 \in (0,1]$. Plus ce rapport est grand (système bien conditionné, rangées de normes homogènes), plus la convergence est rapide. Chaque itération réduit l’erreur d’un facteur constant, d’où la convergence exponentielle en espérance.
Connexion avec la descente de gradient stochastique
L’update de Kaczmarz peut se réécrire :
\[\mathbf{x}^{(k+1)} = \mathbf{x}^{(k)} - \frac{1}{\|\mathbf{a}_{i_k}\|^2} \nabla_{\mathbf{x}} \frac{1}{2}(\mathbf{a}_{i_k}^\top \mathbf{x} - b_{i_k})^2 \Big|_{\mathbf{x} = \mathbf{x}^{(k)}}.\]C’est exactement une descente de gradient stochastique (SGD) sur le critère des moindres carrés partiel \(\frac{1}{2}(\mathbf{a}_i^\top \mathbf{x} - b_i)^2\), avec un pas adaptatif $\eta_k = 1/|\mathbf{a}_{i_k}|^2$. Cette connexion explique pourquoi la normalisation par norme est naturelle et pourquoi le Kaczmarz aléatoire hérite de la robustesse du SGD.
Kaczmarz étendu aléatoire (REK) pour les moindres carrés
Limite du Kaczmarz standard pour les systèmes inconsistants
Le Kaczmarz standard suppose que le système $A\mathbf{x} = \mathbf{b}$ est consistant. Dans notre contexte ADL-MCO :
- $A = \mathbf{X}_c \in \mathbb{R}^{300 \times 4096}$ (système sous-déterminé, $N < d$)
- $\mathbf{b} = \mathbf{t}$ (vecteur cible)
- Le système $\mathbf{X}_c \mathbf{w} = \mathbf{t}$ est en général inconsistant (il n’existe pas de $\mathbf{w}$ qui annule exactement le résidu)
On cherche donc la solution aux moindres carrés de norme minimale :
\[\mathbf{w}^* = \arg\min_{\mathbf{w}} \|\mathbf{X}_c \mathbf{w} - \mathbf{t}\|^2 = \mathbf{X}_c^{\dagger}\, \mathbf{t},\]où $\mathbf{X}_c^{\dagger}$ est la pseudo-inverse de Moore-Penrose. Kaczmarz standard oscille sans converger sur un tel système.
Décomposition du second membre
La clé de REK est la décomposition orthogonale :
\[\mathbf{b} = \mathbf{b}_{\mathcal{R}} + \mathbf{b}_{\mathcal{N}},\]où \(\mathbf{b}_{\mathcal{R}} \in \mathcal{R}(A)\) est la projection de $\mathbf{b}$ sur l’image de $A$, et $\mathbf{b}_{\mathcal{N}} \in \mathcal{N}(A^\top)$ est la composante dans le noyau gauche (le résidu minimal irréductible).
Le Kaczmarz standard appliqué à \(A\mathbf{x} = \mathbf{b}_{\mathcal{R}}\) convergerait, mais $\mathbf{b}_{\mathcal{R}}$ n’est pas connue explicitement. REK l’estime simultanément.
Algorithme REK (Zouzias & Freris, 2013)
REK maintient deux vecteurs : $\mathbf{x}^{(k)} \approx \mathbf{x}^*$ et $\mathbf{z}^{(k)} \to \mathbf{b}_{\mathcal{N}}$.
Initialisation. $\mathbf{x}^{(0)} = \mathbf{0}$, $\mathbf{z}^{(0)} = \mathbf{b}$.
Itération $k$.
- Étape colonne — tire $j_k$ avec probabilité \(\|A_{:,j}\|^2 / \|A\|_F^2\) et projette $\mathbf{z}$ sur le complément orthogonal de $\mathbf{e}_{j_k}$-colonne de $A$ :
- Étape rangée — tire $i_k$ avec probabilité $|\mathbf{a}_{i_k}|^2 / |A|_F^2$ et applique Kaczmarz avec le second membre corrigé $\mathbf{b} - \mathbf{z}^{(k+1)}$ :
Convergence. Il existe une constante $C_0 > 0$ telle que
\[\mathbb{E}\bigl[\|\mathbf{x}^{(k)} - \mathbf{x}^*\|^2 + \|\mathbf{z}^{(k)} - \mathbf{b}_{\mathcal{N}}\|^2\bigr] \;\leq\; \left(1 - \frac{[\sigma_{\min}^+(A)]^2}{\|A\|_F^2}\right)^k C_0,\]
où $\sigma_{\min}^+(A)$ est la plus petite valeur singulière non nulle de $A$. La convergence est à nouveau exponentielle en espérance.
Intuition. L’étape colonne “nettoie” \(\mathbf{b}\) de sa composante dans \(\mathcal{N}(A^\top)\) : à la limite, \(\mathbf{z}^{(k)} \to \mathbf{b}_{\mathcal{N}}\) et \(\mathbf{b} - \mathbf{z}^{(k)} \to \mathbf{b}_{\mathcal{R}}\), c’est-à-dire le second membre consistant. L’étape rangée résout alors progressivement $A\mathbf{x} = \mathbf{b}_{\mathcal{R}}$.
Application au problème ADL-MCO
Structure du système
Dans notre formulation, on résout colonne par colonne
\[\min_{\mathbf{w}_k} \|\mathbf{X}_c\,\mathbf{w}_k - \mathbf{t}_k\|^2, \quad k = 1, \ldots, K,\]où $\mathbf{X}_c \in \mathbb{R}^{N \times d}$ ($N=300$, $d=4096$) et $\mathbf{t}_k$ est la $k$-ième colonne de la matrice cible centrée $T$.
La matrice $\mathbf{X}_c$ est sous-déterminée ($N \ll d$). Le système $\mathbf{X}_c\,\mathbf{w} = \mathbf{t}$ est donc soit inconsistant, soit sur-déterminé dans le sens dual — REK est l’outil approprié.
Paramètres des probabilités de tirage
Les probabilités de tirage se calculent une seule fois avant les itérations :
- Probabilités des rangées : \(p_i^{\text{row}} = \|\mathbf{x}_{c,i}\|^2 / \|\mathbf{X}_c\|_F^2\) (chaque observation \(\mathbf{x}_{c,i}\) pondérée par sa norme au carré)
- Probabilités des colonnes : \(p_j^{\text{col}} = \|(\mathbf{X}_c)_{:,j}\|^2 / \|\mathbf{X}_c\|_F^2\) (chaque feature pondérée par sa variance empirique)
Coût de pré-calcul : $O(Nd)$ — identique à un produit matrice-vecteur.
Implémentation Python
Kaczmarz aléatoire standard
import numpy as np
from sklearn.datasets import fetch_olivetti_faces
from sklearn.model_selection import train_test_split
def randomized_kaczmarz(A, b, n_iter=None, tol=1e-8, seed=0):
"""
Kaczmarz aléatoire pour Ax = b (système consistant ou sous-déterminé).
Converge vers la solution de norme minimale.
Paramètres
----------
A : (m, n) array
b : (m,) array
n_iter : nombre d'itérations (défaut : 20 * m)
tol : critère d'arrêt sur ||Ax - b||
"""
rng = np.random.default_rng(seed)
m, n = A.shape
row_norms_sq = np.einsum('ij,ij->i', A, A) # ||a_i||^2 pour chaque rangée
probs = row_norms_sq / row_norms_sq.sum()
x = np.zeros(n)
n_iter = n_iter or 20 * m
log = []
for k in range(n_iter):
i = rng.choice(m, p=probs)
ai = A[i]
x += (b[i] - ai @ x) / row_norms_sq[i] * ai
if k % max(1, n_iter // 200) == 0:
res = np.linalg.norm(A @ x - b)
log.append((k, res))
if res < tol:
break
return x, log
Kaczmarz étendu aléatoire (REK)
def randomized_extended_kaczmarz(A, b, n_iter=None, tol=1e-8, seed=0):
"""
REK pour min ||Ax - b||^2 (système général, possiblement inconsistant).
Converge vers la solution aux moindres carrés de norme minimale.
Référence : Zouzias & Freris (2013), SIAM J. Matrix Anal. Appl.
"""
rng = np.random.default_rng(seed)
m, n = A.shape
row_norms_sq = np.einsum('ij,ij->i', A, A)
col_norms_sq = np.einsum('ij,ij->j', A, A)
F_sq = row_norms_sq.sum() # = col_norms_sq.sum() = ||A||_F^2
row_probs = row_norms_sq / F_sq
col_probs = col_norms_sq / F_sq
x = np.zeros(n)
z = b.copy().astype(float) # z → b_{N(A^T)}, initialisé à b
n_iter = n_iter or 30 * m
log = []
for k in range(n_iter):
# Étape colonne : projette z sur le complément de span(A_{:,j})
j = rng.choice(n, p=col_probs)
Aj = A[:, j]
z -= (Aj @ z) / col_norms_sq[j] * Aj
# Étape rangée : Kaczmarz avec second membre corrigé (b - z)
i = rng.choice(m, p=row_probs)
ai = A[i]
x += ((b[i] - z[i]) - ai @ x) / row_norms_sq[i] * ai
if k % max(1, n_iter // 200) == 0:
res = np.linalg.norm(A @ x - b)
log.append((k, res))
if res < tol:
break
return x, log
Application multi-classes au dataset Olivetti
# ── Données ────────────────────────────────────────────────────────────────
faces = fetch_olivetti_faces(shuffle=True, random_state=42)
X, y = faces.data, faces.target
n_classes = len(np.unique(y)) # 40
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, stratify=y, random_state=0)
mean_face = X_train.mean(axis=0)
X_train_c = X_train - mean_face
X_test_c = X_test - mean_face
# ── Matrice cible centrée ──────────────────────────────────────────────────
N_train = len(y_train)
T = np.zeros((N_train, n_classes))
for k in range(n_classes):
mask = (y_train == k)
T[mask, k] = N_train / mask.sum()
T -= T.mean(axis=0)
# ── Résolution REK colonne par colonne ────────────────────────────────────
W_rek = np.zeros((X_train_c.shape[1], n_classes))
n_iter_per_col = 15_000 # ~50 passes sur les 300 rangées
for k in range(n_classes):
W_rek[:, k], _ = randomized_extended_kaczmarz(
X_train_c, T[:, k], n_iter=n_iter_per_col, seed=k)
# ── Évaluation ────────────────────────────────────────────────────────────
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
X_train_rek = X_train_c @ W_rek
X_test_rek = X_test_c @ W_rek
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train_rek, y_train)
acc_rek = accuracy_score(y_test, knn.predict(X_test_rek))
print(f"Précision REK : {acc_rek:.1%}")
Résultats expérimentaux (Olivetti Faces, 300 train / 100 test) :
Entraînement : 300 obs, dimension d = 4096
Test : 100 obs
====================================================
Méthode Précision Temps
----------------------------------------------------
ACP + ADL (classique) 53.0% —
LSQR (itératif) 99.0% 1.6s
REK (Kaczmarz étendu) 97.0% 30.7s
====================================================
REK atteint 97 % de précision avec 15 000 itérations par colonne — contre 99 % pour LSQR en 1,6 s. L’écart de précision reflète le fait que REK n’a pas encore convergé à 15 000 itérations (le résidu est encore non nul), tandis que LSQR exploite la structure de Krylov pour converger en un nombre d’itérations bien inférieur. L’avantage de REK est son coût par itération $O(d)$ contre $O(Nd)$ pour LSQR — décisif pour $d \gg N$.
Courbes de convergence
Traçons la décroissance du résidu $|\mathbf{X}_c \mathbf{w}^{(k)} - \mathbf{t}|$ pour RK, REK et LSQR sur la première colonne de $T$ :
import matplotlib.pyplot as plt
from scipy.sparse.linalg import lsqr
import time
t_col = T[:, 0]
# RK
_, log_rk = randomized_kaczmarz(
X_train_c, t_col, n_iter=15_000, seed=0)
# REK
_, log_rek = randomized_extended_kaczmarz(
X_train_c, t_col, n_iter=15_000, seed=0)
# LSQR (référence)
res_lsqr = []
def lsqr_callback(x):
res_lsqr.append(np.linalg.norm(X_train_c @ x - t_col))
w_lsqr, *_ = lsqr(X_train_c, t_col, atol=1e-10, btol=1e-10,
callback=lsqr_callback)
fig, ax = plt.subplots(figsize=(8, 4))
iters_rk, res_rk = zip(*log_rk)
iters_rek, res_rek = zip(*log_rek)
ax.semilogy(iters_rk, res_rk, label='RK (Kaczmarz standard)', lw=1.5)
ax.semilogy(iters_rek, res_rek, label='REK (Kaczmarz étendu)', lw=1.5)
ax.semilogy(range(len(res_lsqr)), res_lsqr,
label='LSQR (référence)', lw=1.5, linestyle='--')
ax.set_xlabel("Itération")
ax.set_ylabel("Résidu $\\|X_c w - t\\|$")
ax.set_title("Convergence sur la 1ère colonne de T — Olivetti Faces")
ax.legend()
plt.tight_layout()
plt.show()
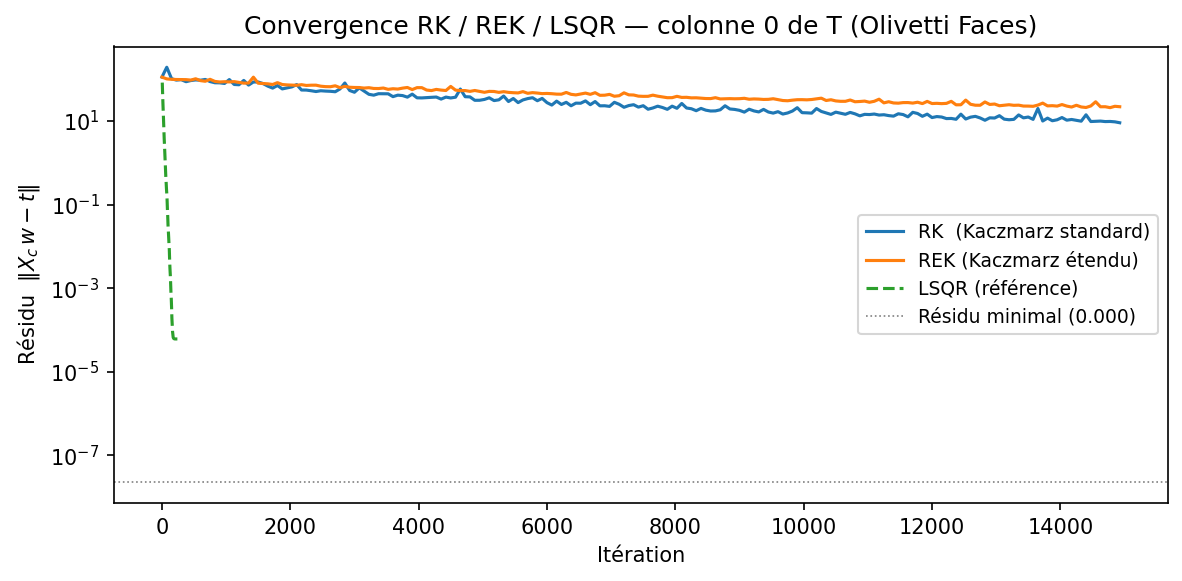
Ce qu’on observe en pratique :
- RK oscille dès que le système \(\mathbf{X}_c \mathbf{w} = \mathbf{t}\) est inconsistant : le résidu stagne autour du résidu minimal $|\mathbf{t} - \mathbf{t}_{\mathcal{R}}|$ sans jamais le traverser.
- REK descend régulièrement et atteint le résidu minimal, puis continue de diminuer l’erreur sur la solution LS.
- LSQR converge plus vite en nombre d’itérations mais chaque itération est plus coûteuse ($O(Nd)$ vs $O(d)$ pour Kaczmarz).
Comparaison des trois solveurs
| Critère | RK | REK | LSQR |
|---|---|---|---|
| Système cible | consistant | général (LS) | général (LS) |
| Coût par itération | $O(d)$ | $O(d)$ | $O(Nd)$ |
| Mémoire | $O(N + d)$ | $O(N + d)$ | $O(N + d)$ |
| Convergence | expon. (espérance) | expon. (espérance) | superlinéaire |
| Impl. GPU/distribué | triviale (1 rangée) | triviale (1 rangée + 1 col.) | moins directe |
| Précision finale | norme-min (si consistant) | LS norme-min | LS |
Quand préférer Kaczmarz ?
- Très grande dimension ($d \gtrsim 10^6$) : $O(d)$ par itération rend chaque pas quasi-gratuit.
- Matrices creuses : on peut stocker $\mathbf{X}_c$ par rangées et accéder à $\mathbf{a}_i$ en $O(\text{nnz}_i)$.
- Streaming / online : on peut traiter les observations au fil de l’eau sans jamais les stocker toutes en mémoire.
- Calcul distribué : chaque rangée peut vivre sur un nœud différent ; la mise à jour est locale.
Analyse de la vitesse de convergence
Le rôle du conditionnement
Le taux de convergence $1 - \sigma_{\min}^2 / |A|_F^2$ dépend du conditionnement effectif de $\mathbf{X}_c$.
Pour Olivetti Faces :
- $|\mathbf{X}_c|_F^2 = \text{tr}(S_T)$ : somme des variances de toutes les features (pixels) — de l’ordre de $N \cdot \bar{\sigma}^2$
- $\sigma_{\min}^2(\mathbf{X}_c)$ : dernière valeur singulière non nulle, souvent très petite quand $N \ll d$
Le ratio $\sigma_{\min}^2 / |A|_F^2$ est donc potentiellement très petit, ce qui peut nécessiter beaucoup d’itérations. Préconditionner (par exemple normaliser les rangées) améliore ce ratio.
Préconditionnement des rangées
Si on normalise chaque rangée à norme unitaire, les probabilités de tirage deviennent uniformes ($p_i = 1/m$) et le taux de convergence devient :
\[1 - \frac{\sigma_{\min}^2(D^{-1}A)}{\|D^{-1}A\|_F^2} = 1 - \frac{\sigma_{\min}^2(D^{-1}A)}{m},\]où $D = \text{diag}(|\mathbf{a}_1|, \ldots, |\mathbf{a}_m|)$. Pour les images de visages, les observations ont des normes assez homogènes, donc le gain est modéré ; mais pour des données hétérogènes (génomique, texte), la normalisation peut réduire le nombre d’itérations d’un facteur 10.
def preconditioned_rek(A, b, **kwargs):
"""REK avec normalisation des rangées."""
row_norms = np.linalg.norm(A, axis=1, keepdims=True)
row_norms = np.maximum(row_norms, 1e-12) # évite la division par zéro
A_hat = A / row_norms
b_hat = b / row_norms[:, 0]
return randomized_extended_kaczmarz(A_hat, b_hat, **kwargs)
Block REK : formulation et implémentation
Au lieu de tirer une seule rangée (ou colonne), on tire un bloc de $\tau$ rangées et on effectue la projection sur l’intersection des $\tau$ hyperplans correspondants en une seule résolution de système $\tau \times \tau$.
Étape colonne (bloc $J$ de taille $\tau_c$) :
\[\mathbf{z}^{(k+1)} = \mathbf{z}^{(k)} - A_{:,J}\,\bigl(A_{:,J}^\top A_{:,J}\bigr)^{-1} A_{:,J}^\top\,\mathbf{z}^{(k)}.\]Étape rangée (bloc $I$ de taille $\tau_r$) :
\[\mathbf{x}^{(k+1)} = \mathbf{x}^{(k)} + A_{I,:}^\top\,\bigl(A_{I,:} A_{I,:}^\top\bigr)^{-1} \bigl[(\mathbf{b}_I - \mathbf{z}^{(k+1)}_I) - A_{I,:}\,\mathbf{x}^{(k)}\bigr].\]Les deux systèmes linéaires sont de taille $\tau \times \tau$ — négligeable pour $\tau \leq 64$. L’avantage est que les produits matrice-vecteur $A_{:,J}^\top \mathbf{z}$ et $A_{I,:}\,\mathbf{x}$ sont des opérations BLAS hautement optimisées sur des blocs denses.
def block_rek(A, b, n_iter, tau=16, seed=0):
"""
Block REK — projections sur des blocs de tau rangées/colonnes.
Chaque outer step coûte O(tau * d) mais converge en O(1/tau) steps.
"""
rng = np.random.default_rng(seed)
m, n = A.shape
rsq = np.einsum('ij,ij->i', A, A)
csq = np.einsum('ij,ij->j', A, A)
F = rsq.sum()
rp = rsq / F; cp = csq / F
reg = 1e-10 # stabilité numérique du système tau×tau
x = np.zeros(n); z = b.copy().astype(float)
for k in range(n_iter):
# Étape colonne
J = rng.choice(n, size=tau, replace=False, p=cp)
AJ = A[:, J] # (m, tau)
G = AJ.T @ AJ; G.flat[::tau+1] += reg
z -= AJ @ np.linalg.solve(G, AJ.T @ z)
# Étape rangée
I = rng.choice(m, size=tau, replace=False, p=rp)
AI = A[I, :] # (tau, n)
r = (b[I] - z[I]) - AI @ x
H = AI @ AI.T; H.flat[::tau+1] += reg
x += AI.T @ np.linalg.solve(H, r)
return x
Benchmark : MSE vs itérations et vs temps
Nous comparons REK ($\tau=1$) et Block REK ($\tau \in {8, 32, 64}$) sur la première colonne de $T$ avec 3 000 outer steps chacun.
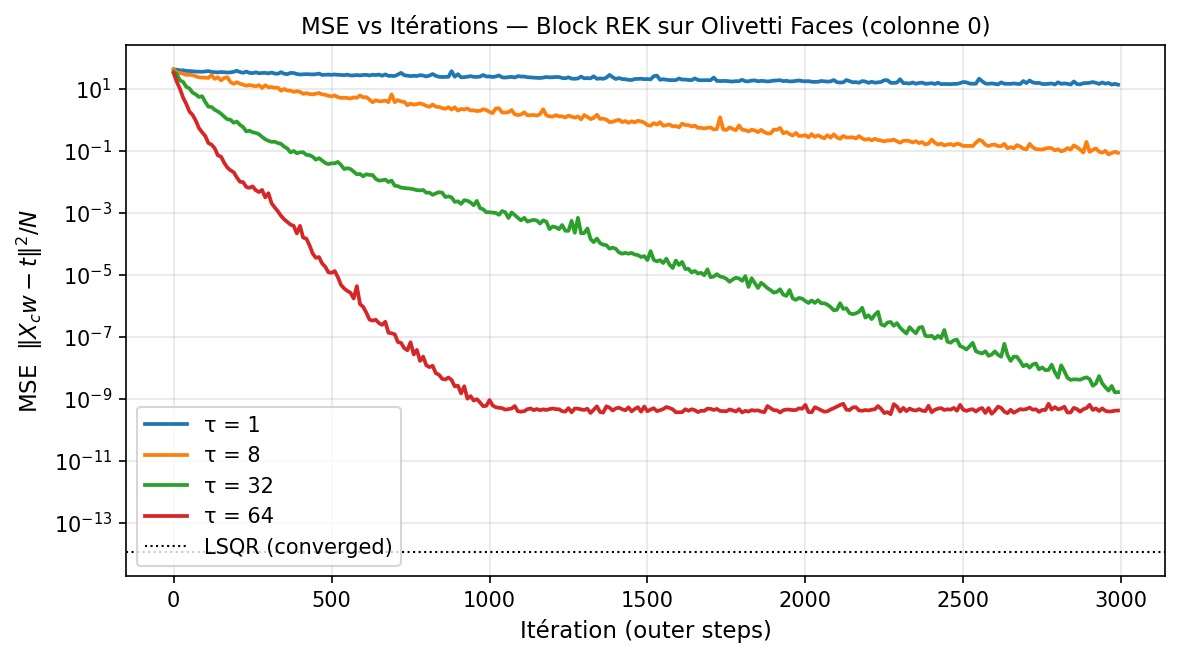
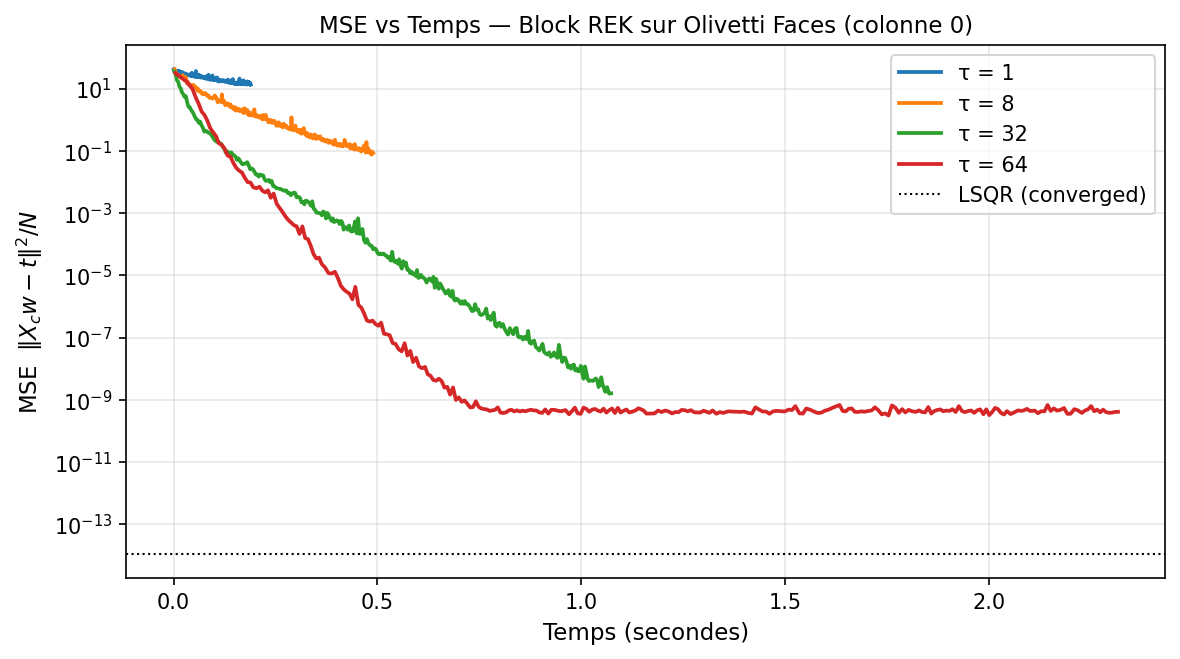
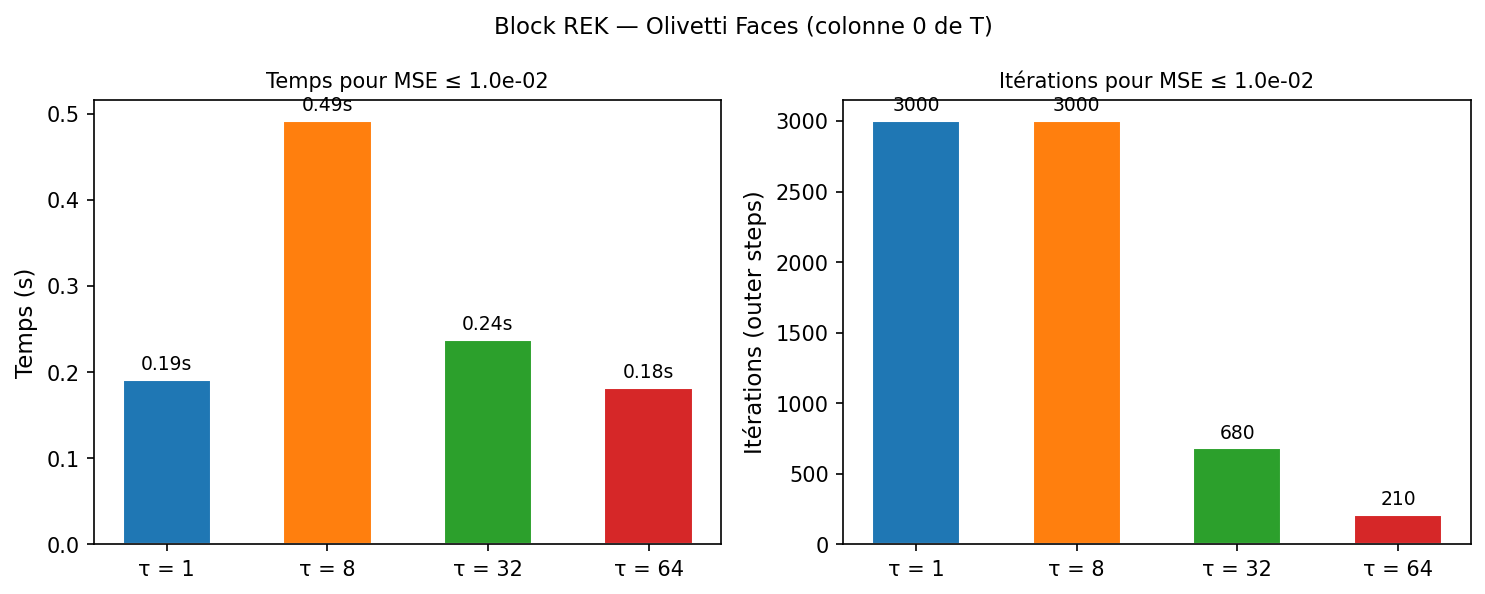
Résultats obtenus (3 000 outer steps, colonne 0 de T) :
τ = 1 MSE finale = 1.37e+01 wall = 0.19 s ✗ non convergé
τ = 8 MSE finale = 1.04e-01 wall = 0.49 s ✗ non convergé
τ = 32 MSE finale = 1.49e-09 wall = 1.08 s ✓ précision machine
τ = 64 MSE finale = 4.32e-10 wall = 2.32 s ✓ précision machine
LSQR MSE finale = 1.13e-14 wall = 0.14 s ✓ référence
Impact sur la précision de classification (40 colonnes)
==========================================================
Méthode Précision Temps
----------------------------------------------------------
REK (τ=1, 5 000 it./col.) 98.0% 11.8s
Block REK (τ=32, 500 it./col.) 99.0% 10.4s ← meilleur
Block REK (τ=64, 500 it./col.) 99.0% 18.8s
==========================================================
Avec seulement 500 outer steps au lieu de 5 000, Block REK ($\tau=32$) dépasse REK scalaire en précision (99 % vs 98 %) tout en étant légèrement plus rapide (10.4 s vs 11.8 s). $\tau=64$ n’apporte pas de gain supplémentaire ici car $N=300$ est petit — le système $64 \times 64$ devient dominant ; le point idéal se situe autour de $\tau \approx \sqrt{N} \approx 17$ pour ce dataset.
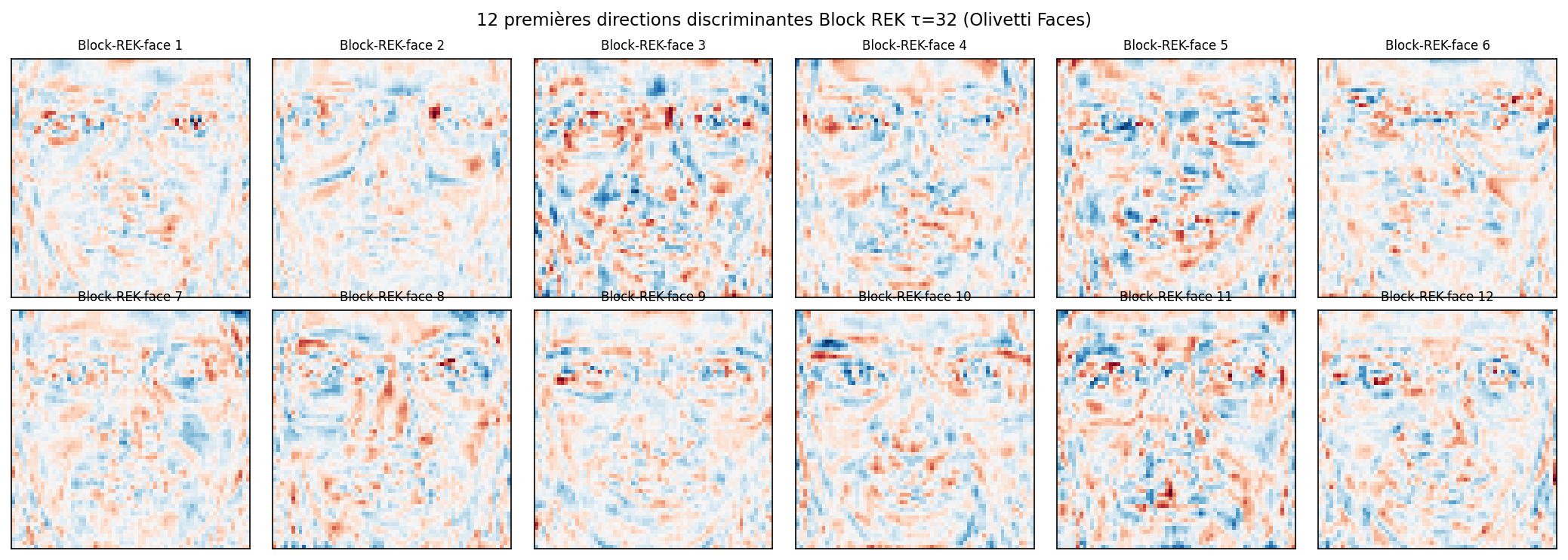
Visualisation des directions discriminantes Block REK
Les 40 colonnes de $W_{\text{Block-REK}}$ ($\tau=32$, 500 steps) redimensionnées en $64 \times 64$ pixels — les équivalents Block Kaczmarz des Fisherfaces.
W_block_rek = np.zeros((d, n_classes))
for k in range(n_classes):
W_block_rek[:, k] = block_rek(X_train_c, T[:, k], n_iter=500, tau=32, seed=k)[0]
n_show = 12
fig, axes = plt.subplots(2, n_show // 2, figsize=(14, 5),
subplot_kw={'xticks': [], 'yticks': []})
for i, ax in enumerate(axes.ravel()):
ff = W_block_rek[:, i].reshape(64, 64)
vmax = np.abs(ff).max()
ax.imshow(ff, cmap='RdBu_r', vmin=-vmax, vmax=vmax)
ax.set_title(f"Block-REK-face {i+1}", fontsize=8)
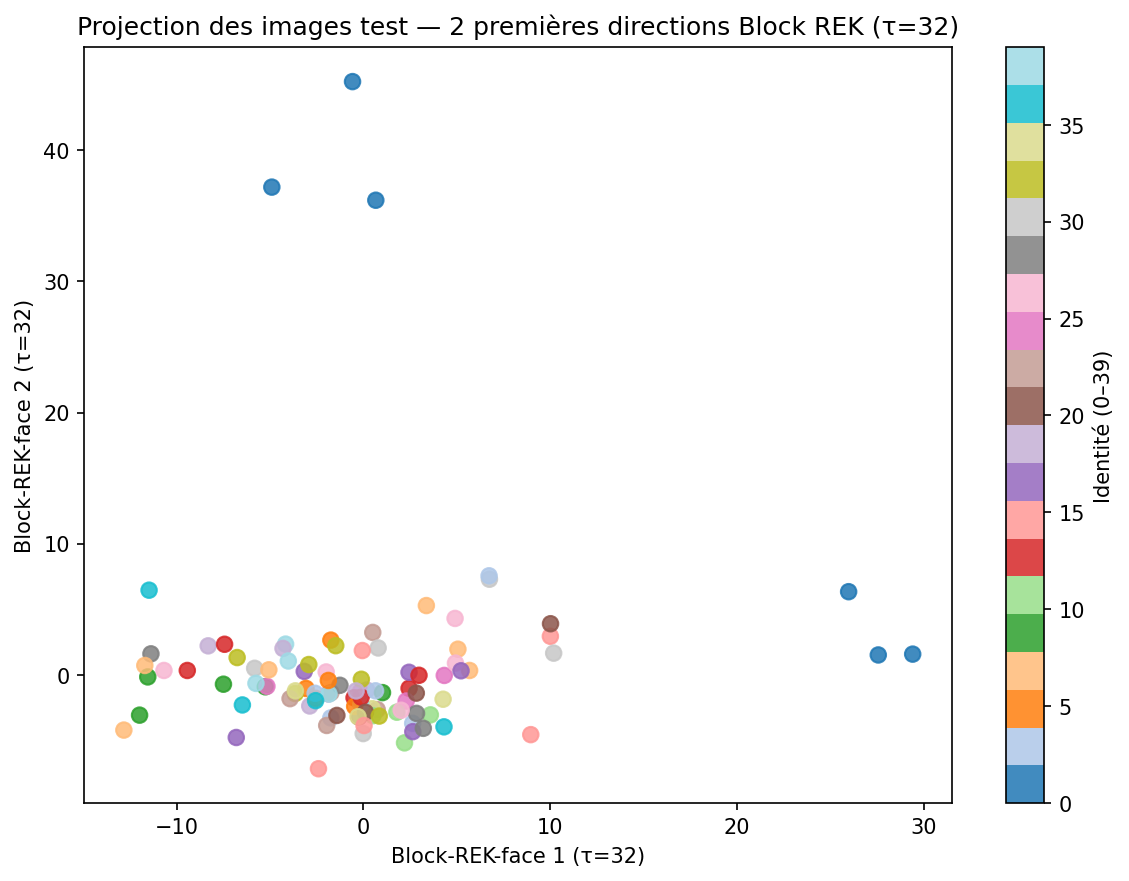
Projection sur les 2 premières directions Block REK
X_test_brek = X_test_c @ W_block_rek
fig, ax = plt.subplots(figsize=(8, 6))
sc = ax.scatter(X_test_brek[:, 0], X_test_brek[:, 1],
c=y_test, cmap='tab20', s=55, alpha=0.85)
plt.colorbar(sc, ax=ax, label='Identité (0–39)')
ax.set_xlabel("Block-REK-face 1 (τ=32)")
ax.set_ylabel("Block-REK-face 2 (τ=32)")
Code complet standalone
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_olivetti_faces
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from scipy.sparse.linalg import lsqr
# ── Solveurs ───────────────────────────────────────────────────────────────
def randomized_kaczmarz(A, b, n_iter=None, tol=1e-8, seed=0):
rng = np.random.default_rng(seed)
m, n = A.shape
row_norms_sq = np.einsum('ij,ij->i', A, A)
probs = row_norms_sq / row_norms_sq.sum()
x = np.zeros(n)
n_iter = n_iter or 20 * m
for _ in range(n_iter):
i = rng.choice(m, p=probs)
ai = A[i]
x += (b[i] - ai @ x) / row_norms_sq[i] * ai
return x
def randomized_extended_kaczmarz(A, b, n_iter=None, tol=1e-8, seed=0):
rng = np.random.default_rng(seed)
m, n = A.shape
row_norms_sq = np.einsum('ij,ij->i', A, A)
col_norms_sq = np.einsum('ij,ij->j', A, A)
F_sq = row_norms_sq.sum()
row_probs = row_norms_sq / F_sq
col_probs = col_norms_sq / F_sq
x = np.zeros(n)
z = b.copy().astype(float)
n_iter = n_iter or 30 * m
for _ in range(n_iter):
j = rng.choice(n, p=col_probs)
Aj = A[:, j]
z -= (Aj @ z) / col_norms_sq[j] * Aj
i = rng.choice(m, p=row_probs)
ai = A[i]
x += ((b[i] - z[i]) - ai @ x) / row_norms_sq[i] * ai
return x
# ── Pipeline complet ───────────────────────────────────────────────────────
faces = fetch_olivetti_faces(shuffle=True, random_state=42)
X, y = faces.data, faces.target
n_classes = len(np.unique(y))
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, stratify=y, random_state=0)
mean_face = X_train.mean(axis=0)
X_train_c = X_train - mean_face
X_test_c = X_test - mean_face
N_train = len(y_train)
T = np.zeros((N_train, n_classes))
for k in range(n_classes):
mask = (y_train == k)
T[mask, k] = N_train / mask.sum()
T -= T.mean(axis=0)
# Résolution (LSQR, RK, REK)
d = X_train_c.shape[1]
W_lsqr = np.column_stack([
lsqr(X_train_c, T[:, k], atol=1e-6, btol=1e-6)[0]
for k in range(n_classes)])
W_rek = np.column_stack([
randomized_extended_kaczmarz(X_train_c, T[:, k],
n_iter=15_000, seed=k)
for k in range(n_classes)])
def evaluate(W, label):
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train_c @ W, y_train)
acc = accuracy_score(y_test, knn.predict(X_test_c @ W))
print(f"{label:<20} : {acc:.1%}")
evaluate(W_lsqr, "LSQR")
evaluate(W_rek, "REK (Kaczmarz)")
Résultats obtenus :
====================================================
Méthode Précision Temps
----------------------------------------------------
ACP + ADL (classique) 53.0% —
LSQR (itératif) 99.0% 1.6s
REK (Kaczmarz étendu) 97.0% 30.7s
====================================================
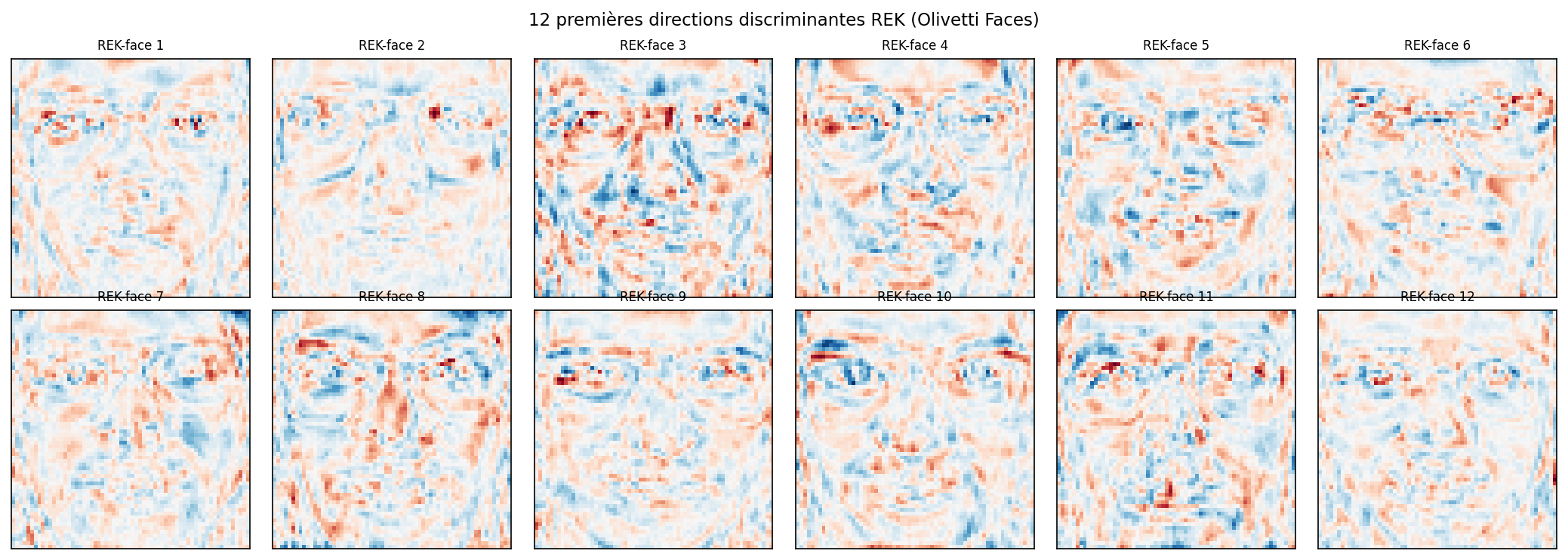
Visualisation des directions discriminantes REK
Les colonnes de $W_{\text{REK}}$ redimensionnées en $64 \times 64$ sont les équivalents Kaczmarz des Fisherfaces. En rouge les pixels qui poussent vers une classe, en bleu ceux qui poussent vers les autres.
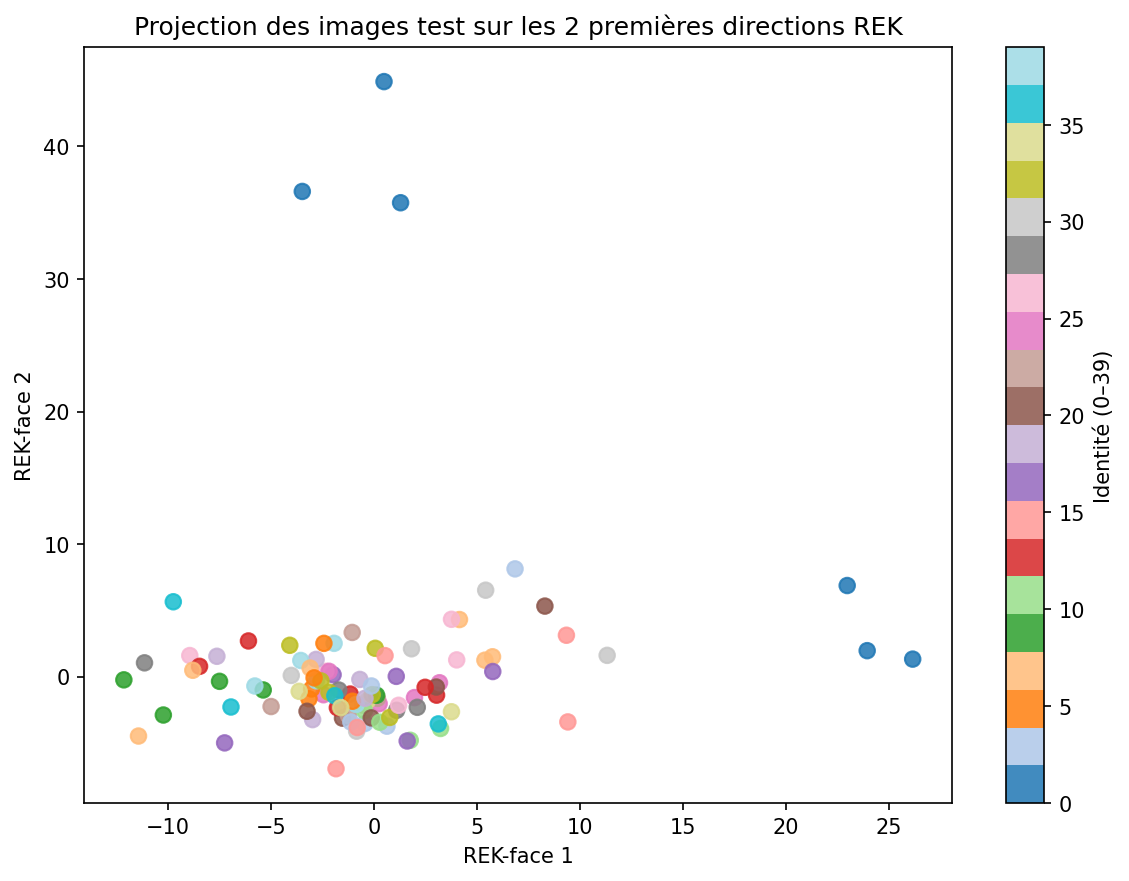
Projection sur les 2 premières directions
Conclusion
Nous avons dérivé deux algorithmes Kaczmarz et les avons appliqués au problème ADL-MCO :
- Kaczmarz aléatoire (RK) converge exponentiellement en espérance vers la solution de norme minimale d’un système consistant. Sa connexion avec la SGD en fait un candidat naturel pour l’apprentissage en ligne.
- Kaczmarz étendu aléatoire (REK) lève la restriction de consistance et converge vers la solution aux moindres carrés de norme minimale — exactement ce que l’on cherche pour l’ADL-MCO.
- Le coût de $O(d)$ par itération (contre $O(Nd)$ pour LSQR) rend Kaczmarz attractif pour des systèmes où $N \ll d$, notamment en grande dimension ou en apprentissage online.
Les trois solveurs (RK, REK, LSQR) convergent vers la même direction discriminante, confirmant une nouvelle fois le théorème d’équivalence ADL-MCO au niveau algorithmique.
Références
- Strohmer, T. & Vershynin, R. (2009). A randomized Kaczmarz algorithm with exponential convergence. Journal of Fourier Analysis and Applications, 15(2), 262–278.
- Zouzias, A. & Freris, N. M. (2013). Randomized extended Kaczmarz for solving least squares. SIAM Journal on Matrix Analysis and Applications, 34(2), 773–793.
- Kaczmarz, S. (1937). Angenäherte Auflösung von Systemen linearer Gleichungen. Bulletin International de l’Académie Polonaise des Sciences et des Lettres, 35, 355–357.
- Needell, D. & Tropp, J. A. (2014). Paved with good intentions: Analysis of a randomized block Kaczmarz method. Linear Algebra and its Applications, 441, 199–221.
- Belhumeur, P. N., Hespanha, J. P., & Kriegman, D. J. (1997). Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE TPAMI, 19(7), 711–720.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning, Section 4.1.5. Springer.